使用Scratch编写画笔类应用时,我们必须打开Scratch的“选择扩展”窗口,除了画笔,还有音乐、视频侦测、乐高机器人等:
你可以根据需要把扩展加载到Scratch的积木中,就可以调用它们提供的积木了:
Python中我们是怎么实现“扩展”的呢?回顾前面我们调用小海龟绘制图形的程序:
import turtle
turtle.shape('turtle')
turtle.forward(100)
turtle.done()第一行import turtle 就是加载了Python的小海龟画笔“扩展”,不过在Python中,这种功能扩展称为库。Python库是包括相关功能的模块集合。所以我们先来了解自定义模块。
一、模块定义和使用
一个模块就是一个Python文件,也就是说,我们以前建立一个Python文件的时候,其实就是建立一个独立的模块,只不过还没有意识到它可以被其它文件调用而已。
例如:
def add(a, b):
return a+b
def sub(a, b):
return a-b现在,把这个程序保存成mod_1.py,它就成了一个模块。现在,另外建立一个python文件:
import mod_1
print(mod_1.add(1,2))把这个文件保存成mod_2.py,并且要注意和mod_1.py保存到一个目录。现在运行mod_2.py,你会发现输出了1和2相加的结果3。mod_2并没有实现加法,它是调用了mod1中的add()函数实现的。你可能会觉得,这么简单的代码我为什么非要写到两个文件中呢?首先,这只是一个示例,我们不能写得太复杂;其次,只要这段代码是具有通用价值,可以被其它模块调用的,我们就可以把它们放在单独的模块中,减少以后编写同样代码的工作量,也可以让程序结构更清晰,这和自定义函数是一个道理。
其实,你不妨把自定义模块理解为“自定义函数”和“自定义数据”的集合,都是为了方便重复使用它们,让我们以后的编程更方便。
现在我们总结一下导入模块的方法。一般来说 ,导入模块的方式有两种: – 全部导入:import + 文件名,导入模块所有内容,使用时要指定使用哪个模块的哪个部分。前面我们导入mod_1的方式就是如此。如果模块名字很长,你还可以使用as关键字,给导入的模块起一个别名,在程序中直接使用别名就可以了:
import mod_1 as m1
print(m1.add(1,2))- 部分导入:from + 模块名 + import + 函数名,可以只导入这个模块的指定函数。这样在程序中可以直接使用函数名,不需要在前面加模块名,比如:
from mod_1 import add
print(add(1,2))这段程序,我们从mod_1模块导入了add这一个函数。你也可以写成 from mod_1 import * 代表导入mod_1的全部函数,这样代码就可以直接调用导入的函数,不用写模块名。
表面上看,这样不写模块名似乎更简单,但是这种方法有一个缺点,就是代码一长,导入的模块和函数多,你可能不知道这个函数是从哪来的。相比之下,还是带上模块名更易理解一些。除非模块太大,否则不建议用这种方式导入。
关于导入使用模块,还有两点需要注意: – 自定义模块的命名要遵循Python的命名规范,和变量类似,由英文字母、数字、下划线组成,不要带中文和特殊字符,而且不要与Python自带的模块重名。比如你如果定义一个turtle模块,那么系统自带的turtle功能你就无法使用了; – 使用模块的程序文件和模块文件需要在一个文件夹中,这样才能被成功导入和使用 – 自定义函数一个模块在程序中只需要导入一次 – 如果你不知道一个模块中有哪些函数,可以使用内置函数dir(),比如你可以这么查看mod_1模块的所有函数:
import mod_1
print(dir(mod_1))运行结果:

你可以看到print打印出来一个列表,列表中最后两项add、sub就是我们定义的函数。那么前面那些’builtins‘之类的是什么呢?这种用两个下划线’__’ 包括起来的内容是Python自动生成的,目前我们先不用管它们,将来会用到的时候再讲。
二、Python库
什么是“库”呢?库就是具有相关功能的模块集合。Python库分为两种,一种是“标准库”,就是安装Python的时候已经安装在系统中的,我们可以直接用import导入它们使用(和导入自定义模块的方法是一样的);另一种就是全世界许许多多的程序员开发的不同功能的“库”,我们称为“第三方库”,它们需要安装到系统中才可以使用。
前面我们使用过的turtle库就是绘图相关的模块集合。今天我们再来学一个标准库random,它是Python提供随机数相关功能的库(你是否想起了Scratch提供的“在…和…之间取随机数”指令?),random的主要应用场景包括两种:
1、生成随机数
导入random库之后,我们可以调用它的random函数生成一个0-1之间的浮点数n(小数),注意0<=n<1。如果要生成随机的整数,可以使用randint()函数,它接收两个参数a、b,返回a和b之间的随机整数(包括a、b这两个值)。例如:
import random # 导入random库,也可以称为random模块
a = random.random() # 注意第一个random是模块名,第二个random是这个模块下的函数
b = random.randint(5,10)
print(a)
print(b)你可以运行这段程序查看一下结果,由于生成的是随机数,所以每次结果可能都不一样。
random库还提供了randrange()函数,它相当于从函数range()生成的序列中随机选取一个数字。因此,这个函数接收的参数和range()函数是一致的,如果只有一个参数,代表结束数值(不包括它本身),起始数值默认为0,步长默认为1;接收两个参数时代表起始数值和结束数值,步长默认为1;接收三个参数时分别为起始数值、结束数值、步长。例如:
import random
a = random.randrange(10) # 生成0-10(不包括10)序列中的一个随机数字;
b = random.randrange(10,50) # 生成10-50(不包括50)序列中的一个随机数字;
c = random.randrange(10,50,2) # 生成10-50(不包括50),步长为2的序列中的一个随机数字;
print(a)
print(b)
print(c)2、随机选择
你拿出一副扑克牌打乱,让玩家随便“抽”一张,这是玩扑克牌时经常见到的场景。程序中也经常要从一个序列中抽取数据。random库提供了choice()、sample()和shuffle()三个常用的函数。 – choice() choice()函数接收序列型参数,随机返回其中的一个元素。比如从列表或元组中抽一个元素,或者从字符串中随机选一个字符等:
import random
list1 = ['关羽','张飞','赵云','黄忠','魏延']
print(random.choice(list1)) # 打印五个英雄中一位的名字- sample() sample()函数从序列或集合中随机抽取若干个元素,并以列表的形式返回。它接收两个参数,第一个是要抽取的序列,第二个是要抽取的元素个数。例如:
import random
list1 = ['关羽','张飞','赵云','黄忠','魏延']
print(random.sample(list1,2)) # 抽取两位英雄名字并打印- shuffle() shuffle是英语“洗牌”的意思,所以shuffle()函数的作用就是把列表中的元素顺序打乱随机排列。比如:
import random
list1 = ['关羽','张飞','赵云','黄忠','魏延']
random.shuffle(list1)
print(list1) # 输出打乱顺序后的列表有了random库的帮助,我们就能实现许多生动有趣的场景了。
三、模块化编程
前面我们已经了解了自定义模块和库,我们再来了解一下广义的“模块”概念。Python中的“模块”就是一个.py文件,实际上,从广义上讲,“模块”是某个事物的一部分。如果某个事物可以被容易地分解成多个部分,我们就说这个事物是可以模块化的。比如我们在玩乐高积木的时候,可以轻易地把不同的积木组合成自己需要的玩具; 同样也可以把它们再拆开组装别的玩具。
“模块化”对我们编程有什么借鉴呢?我们可以把一个大的程序分成几个模块,一个模块中只实现相关的功能函数,这样就是“模块化”编程。“模块化编程”有许多好处: – 让程序结构更清晰,降低编程的复杂度; – 提高代码的复用率。复用就是“重复利用”的意思,下次再编写其它程序的时候,如果现在的模块中有可以重复利用的,直接调用现成的模块就可以,减少了工作量; – 易于扩展和维护程序,也方便阅读、修改和优化代码。
那么怎样做到“模块化”编程呢?我们都知道遇到一个复杂问题时,会采用“分布治之”的思路,把大的问题拆分成小的问题去解决。那么在编程时,我们也可以采用“自顶向下、逐层分解”的方式——先从整体上规划整个系统的功能、性能,然后把程序进行划分,分解成规模较小、功能较为简单的模块,并确定这些模块之间的调用功能——这其实就是“系统架构师”的工作。在大的软件项目中,有专门的系统架构师去完成这些工作,把程序分成小模块分给不同的人编写;我们自己写程序时,只好辛苦一点,又做架构师,又做程序员啦。
模块化编程不是随便模块化的,它有一定的原则,最基本的就是模块内部“高内聚”,模块之间“低耦合”。 – 高内聚:划分模块时把联系紧密的功能放到一个模块中;每个模块只完成单独的功能。 – 低耦合:模块之间要相互独立,除了主程序之外,减少模块之间的相同协助和影响。 “高内聚、低耦合”这两个概念你需要记下来,随着你编程水平的不断提高,你对这两个词语的内涵理解会越来越深入。现在就只需要知道,把相关的放一块,不相关的不要相互影响就可以了。比如,一个模块专门用来做数学计算,那就不要把绘图的函数放进去。 一般来说,模块的内聚程度越高,耦合程度就越低,它们是相互作用的。
四、模块化编程实践
我们用一个实际的例子来讲述“模块化编程”。要求用程序绘制如图所示的蓝色背景,背景上要画出用户指定数量的星星(位置随机分布),你会如何解决问题:
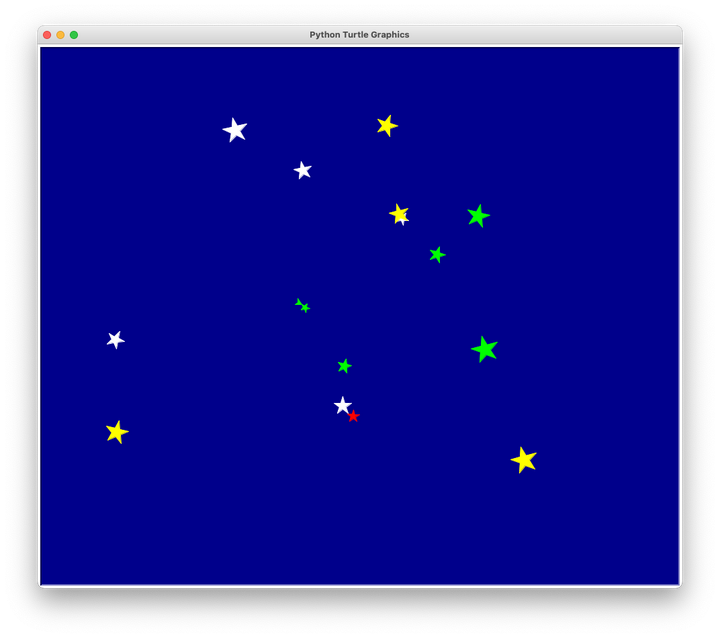
实际上,你可以把这个问题分成几个小问题: – 1、绘制一颗指定颜色和大小的星星 – 2、随机生成星星的位置 – 3、绘制指定数量的随机星星 – 4、用户输入星星数量
第一、二、三个问题我们都可以写成自定义函数,放在单独的文件draw_star.py中:
# draw_star.py
import random
import turtle as t
# 画出指定颜色和大小的星星
def draw_single_star(color, size):
t.color(color,color) # 设置画笔色和填充色
t.pendown()
t.setheading(random.randint(0,360)) # 设置画笔面向的方向
t.begin_fill() # 使用begin_fill()方法开始颜色填充
for i in range(5):
t.forward(size)
t.left(72)
t.forward(size)
t.right(144)
t.end_fill() # 使用end_fill()方法结束颜色填充
# 将小海龟移到随机位置
def change_location():
t.penup()
x = random.randint(-400, 400) # 使用random库生成随机的整数x坐标
y = random.randint(-300, 300) # 使用random库生成随机的整数y坐标
t.goto(x, y)
# 画指定数量的星星
def draw(cnt):
t.bgcolor('darkblue') # 这是turtle库提供的修改背影色函数
for i in range(cnt):
change_location()
color = random.choice(['red', 'yellow', 'green', 'white'])
size = random.randint(5, 15)
draw_single_star(color, size)
t.done()绘图的功能基本都实现了,我们再做一个主程序draw_pic.py,导入draw_star模块,实现绘图:
import draw_star
# 这里使用了一个无限循环,如果用户输入的不是整数,转换会出错,捕获异常要求重新输入
# 用户输入了整数,使用break跳出循环,执行后面的程序
while True:
try:
a = int(input('要画多少个星星?'))
if a > 0:
break
except:
print('请输入整数')
draw_star.draw(a)当然,其实我们现在写的程序功能还是比较简单的,所以模块的代码都不多。程序规模越大,你越能体会到“模块化编程”的好处。
五、课后作业
完成本节课的“绘制星星”程序,并按照你的想法进行完善。
